BPF与eBPF
BPF与eBPF是什么
BPF(Berkeley Packet Filter),伯克利数据包过滤器,这项技术诞生于 1992 年,其作用是提升网络包过滤工具的性能,2014年正式加入Linux内核主线。
BPF 作用
BPF 提供了一种在各种内核事件和应用程序事件发生时候运行一段小程序的机制。
BPF 组成
BPF 由指令集、存储对象、辅助函数等几部分组成
BPF 采用虚拟指令规范,因此也将它视为一种虚拟机实现,BPF 指令由 linux 内核中的运行时模块执行。
BPF 运行时的两种执行机制:1. 解释器;2. 将BPF指令动态转换为本地化指令的即时(JIT)编译器
BPF 执行
在实际执行之前,BPF 指令必须先通过验证器的安全性检查,以确保 BFP 程序自身不会崩溃或者损坏内核
BPF 应用领域
- 网络
- 客观测性
- 安全
扩展后的
BPF就是eBPF,官方的BPF不带e,实际上指的就是 eBPF
名词: 跟踪、嗅探、采样、剖析、可观测性
跟踪(嗅探)
跟踪是基于事件的记录,这也是 BPF 工具所使用的监测方式。比如:strace 可以记录和打印系统调用事件的信息;top 使用固定的计数器统计监测事件的频次。
跟踪工具的一个显著标志是,它具备记录原始事件和事件元数据的能力,既可以是直接输出原始事件,也可以是统计原始事件的频次。
嗅探(跟踪)
嗅探实际上和跟踪指的是一回事,嗅探更多的适用于solaris系统上的跟踪工具
采样
采样工具通过获取全部管测量的子集来描绘目标的大致图像,这也被称为 生成性能剖析样本 或 profiling。比如:profile命令,它基于计时器来对运行中的代码定时采样(每隔10s采样一次)。
采样工具的优点是:其性能开销比跟踪工具小
缺点是:它只提供大致画像,会遗漏事件
可观测性
可观测性指通过全面观测来理解一个系统,可以实现这一目标的工具就可以归纳为可观测性工具。
可观测性工具包括:跟踪工具、采样工具、基于固定计数器的工具。
可观测性工具不包括基准测量工具(benchmark),基准测量工具在系统上模拟业务负载,会更改系统的状态。
编写 BPF 程序(BCC、bpftrace)
直接编写 BPF 程序是繁琐的,在跟踪用途方面,可以使用支持高级语言的 BPF 前端编写 BPF 程序——BCC和bpftrace
BPF编译集合(BPF Compiler Collection, 即BCC)
BCC 是最早用于开发 BPF 跟踪程序的高级框架。它提供了一个编写内核 BPF 程序的 C 语言环境,同时还提供了其它高级语言(如:Python、Lua和C++)环境来实现用户端接口。它也是 libbcc 和 libbpf 库的前身,这两个库提供了使用 BPF 程序对事件进行观测的库函数。
BCC 源代码库中提供了 70 多个 BPF 工具,可以用来支持性能分析和排障工作。
BCC 适合开发复杂的脚本和作为后台进程使用,它还可以调用其它库的支持。比如:使用python开发的BCC程序,还使用python的argparse库来提供复杂、惊喜的工具命令行参数支持。
bpftrace
bpftrace 是新近出现的前端,也是基于 libbcc 和 libbpf 库进行构建的。
bpftrace 适合编写功能强大的单行程序、短小的脚本。
bpftrace 和 BCC 可以互补使用
IO Visor
BCC 和 bpftrace 不在内核代码仓库中,而是属于 IO Visor 的 Linux 基金会项目
BPF 跟踪的能见度
BPF 跟踪可以在整个软件栈范围内提供能见度,允许我们随时根据需要开发新的工具和监测功能。
在生产环境中可以立即部署 BPF 跟踪程序,不需要重启系统,也不需要以特殊方式重启应用软件。
下图展示了一个通用的系统软件栈,用相应的 BPF 性能工具对各个部分进行了标记。工具基本来自 BCC 和 bpftrace。
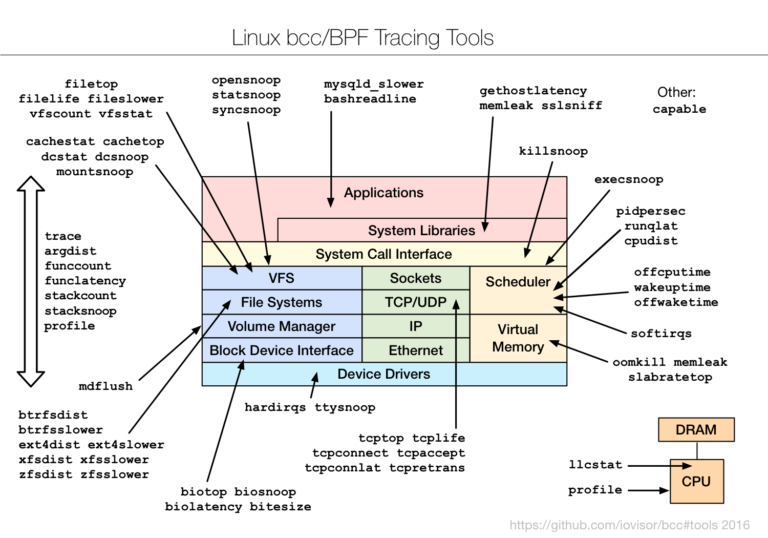
下图列出传统工具与 BPF 工具对组建监测的支持情况
| 组件 | 传统分析工具 | BPF跟踪 |
|---|---|---|
| 基于语言运行时开发的应用程序: Java、Nodee.js、Ruby、PHP |
运行时调试器 | 是,在运行时支持的情况下 |
| 基于编译型代码开发的应用程序: C、C++、Golang |
系统调试器 | 是 |
系统库:/lib/* |
ltrace(1) | 是 |
| 系统调用接口 | strace(1)、perf(1) | 是 |
| 内核:调度器、文件系统、TCP、IP等 | 用于采样的perf(1) | 是,更加详尽 |
| 硬件:CPU核心、设备 | perf、sar、/proc计数器 | 是,直接或间接 (BPF无法直接对设备上的固件进行观测, 可以通过对内核驱动事件或者性能监测计数器PMC进行跟踪,间接推断相关行为) |
传统工具提供的信息可以作为性能分析的起点,后续则可以通过 BPF 跟踪工具做更加深入的调查
动态插桩: kprobes 和 uprobes
动态插桩技术(也叫动态跟踪技术)——在生产环境中对正在运行的软件插入观测点的能力,具体插桩的函数可以是软件栈中运行函数的任意一个(在内核函数或应用函数的开始或结束位置进行插桩)。
动态插桩技术是2012年在Linux上开始支持,具体使用例子如下:
| 探针 | 描述 |
|---|---|
kprobe:vfs_read |
在内核函数vfs_read()的开始位置进行插桩 |
kretprobe:vfs_read |
在内核函数vfs_read()的返回位置处进行插桩 |
uprobe:/bin/bash:readline |
在/bin/bash程序中的readline()函数开始位置进行插桩 |
uretprobe:/bin/bash:readline |
在/bin/bash程序中的readline()函数返回位置进行插桩 |
未启用时候动态插桩开销为0。
动态插桩有一点不好:随着软件版本的变更,被插桩的函数有可能被重新命名,或者移除,导致 BPF 无法正常工作,或者可能打印出一写错误信息;另一个问题是编译器启动优化,把某些函数做内联处理,使得这些函数无法做动态插桩。以上问题,使用静态插桩技术解决。
静态插桩 tracepoint和USDT
静态插桩将稳定的事件名字编码到软件代码中,由开发者维护。BPF 跟踪工具支持内核的静态跟踪点插桩技术,也支持用户态的静态定义跟踪插桩技术USDT(user level statically defined tracing)。
静态插桩问题:增加开发者维护成本,因此软件中的静态插桩要数量有限。
除非需要自己开发 BPF 工具,否则上边提到的静态插桩、动态插桩细节无须关注。如果确实要开发 BPF 工具,一个推荐的策略是:首先尝试静态跟踪技术(跟踪点或USDT),如果不够的话再使用动态跟踪技术(kprobes或uprobes)。
下边是 bpftrace 用到的跟踪点和USDT例子
| 探针 | 描述 |
|---|---|
tracepoint:syscalls:sys_enter_open |
对open(2)系统调用进行插桩 |
usdt:/usr/sbin/mysqld:mysql:query_start |
对/usr/sbin/mysqld程序中的query_start探针进行插桩 |
例子
bpftrace跟踪open()
|
|
输出结果打印了进程的名字和传递给 open(2) 系统调用的文件名: bpftrace 是全系统层面的跟踪,因此任何调用了 open(2) 的应用都能覆盖。
BPF 程序被定义在单引号所包围的代码内,当敲击Enter键运行bpftrace命令时候,它会立即被编译并且运行。
当然 open() 函数还有其它变体,比如:openat(),可以使用如下命令列出所有与open系统调用相关的跟踪点
|
|
BPF 技术原理
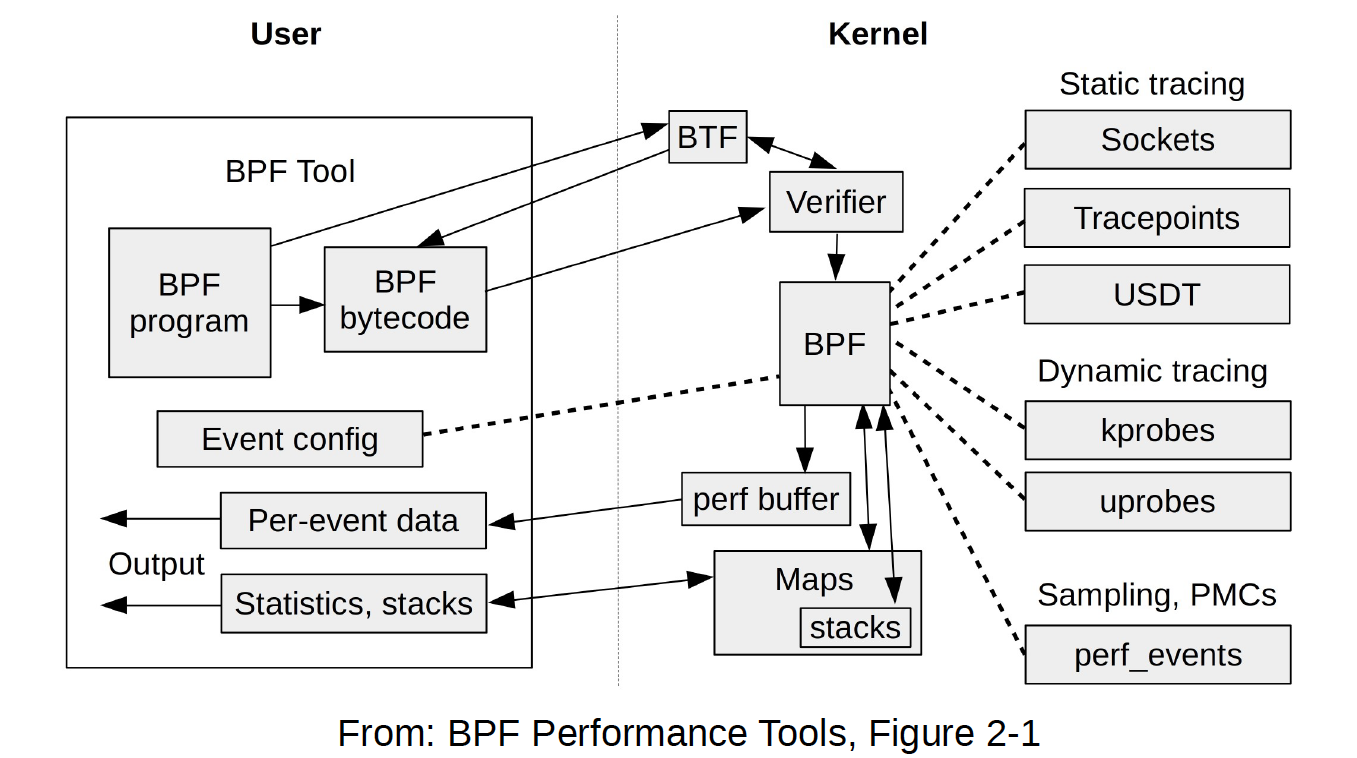
BPF 程序使用 BPF字节码(BPF虚拟机的指令集)定义过滤表达式,然后传递给内核,由解释器执行,无须数据包复制。
BPF 提供了安全保障,用户自定义的过滤器在执行前必须先通过安全性验证,且必须在内核空间执行。
早期BPF和扩展版BPF
- 1997年进入Linux2.1.75:最初BPF被称为“经典BPF”,它是一个功能有限的虚拟机。
- 2011年7月Linux3.0 中增加了BPF即时编译器(just-in-time, JIT),相比解释器来说,它执行效率更高。
- 2012年 Will Drewry 为安全计算系统调用添加了 BPF 过滤器,这是第一次运用在网络领域之外,也先是出BPF可以作为一个通用执行引擎的潜力。
- 2013年12月提议在此之前创造的eBPF合入Linux内核
- 2014年eBPF补丁开始合入Linux内核
- 2014年6月,JIT组件并入Linux内核3.15中
- 2014年12月,用于控制BPF的bpf(2)系统调用进入Linux3.18版本中。之后在Linux4.x内核增加了对
kprobes、uprobes、tracepoints和perf_events的BPF支持。
目前所说的BPF都指eBPF
BPF 运行时
下图展示 BPF 指令如何通过BPF验证器验证,再由BPF虚拟机执行过程:
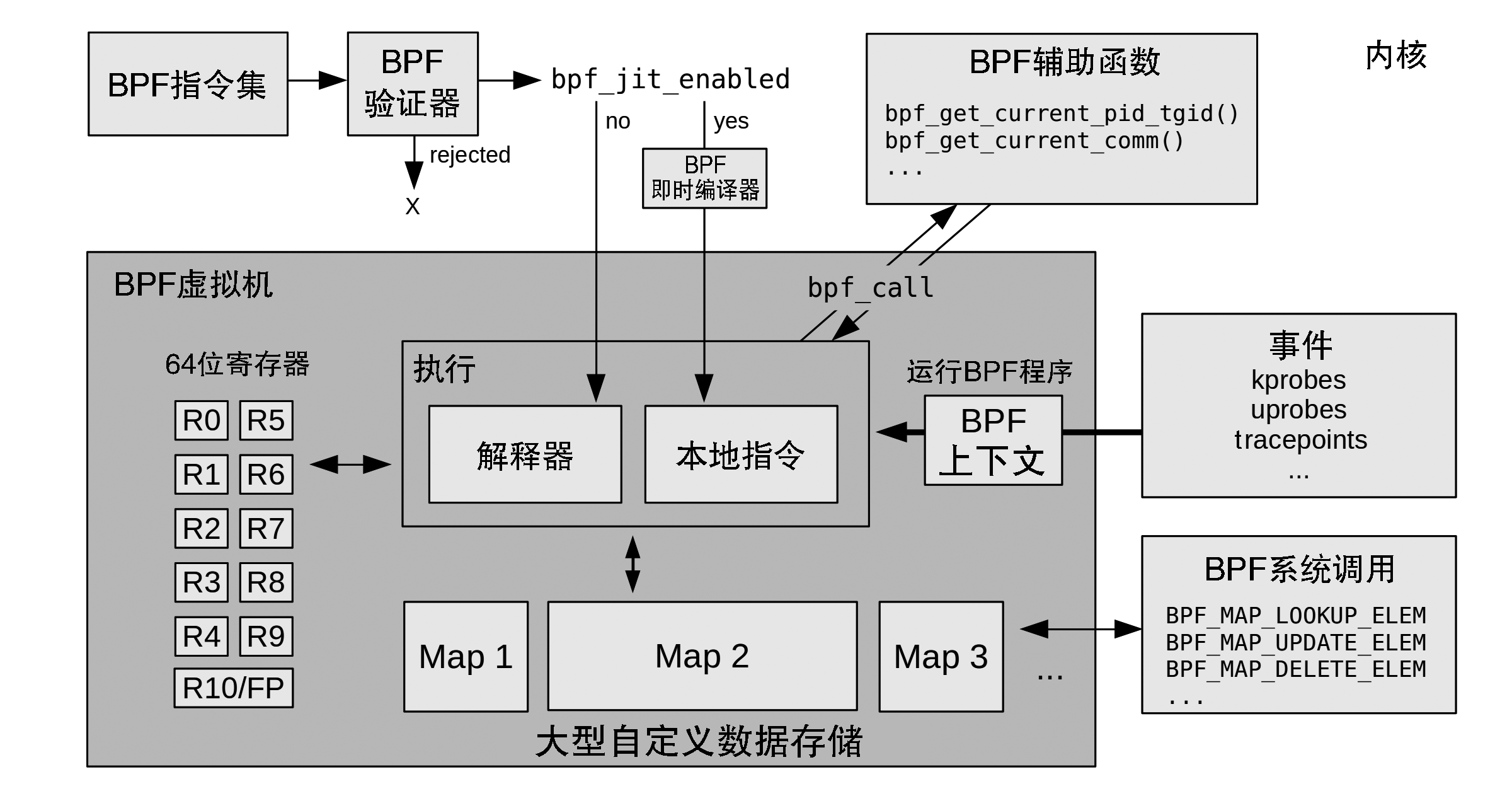
BPF 虚拟机实现包括:解释器和JIT编译器,JIT编译器负责生成处理器可直接执行的机器指令。验证器会拒绝那些不安全的操作,这包括针对无界循环的检查:BPF程序必须在有限的时间内执行完成。
BPF 可以利用辅助函数获取内核状态,利用BPF映射表进行存储。BPF程序在特定事件发生时候执行,包括 kprobes、uprobes和跟踪点等事件。
使用 BPF 或 内核模块实现性能分析工具的思路
….
编写BPF程序
很多前端工具可以用来支持 BPF 编程,在跟踪观测方面,主要的前端按照开发语言从低级到高级排列如下:
- LLVM
- BCC
- bpftrace
LLVM 编译器支持将 BPF 作为编译目标体系结构。BPF 程序可以使用 LLVM 支持的更高级语言编写,比如 C 语言(借助Clang)或LLVM中间表示形式,然后再编译成 BPF。
LLVM 自带优化器,可以对它生成的 BPF 指令进行效率和体积上的优化。
….
留坑后续再填…
参考
- BPF 相关源码所在仓库: https://github.com/iovisor
- 以 Arch Linux 为例,使用 BCC 则执行
pacman -S bcc bcc-tools python-bcc,同时要注意一些内核编译配置。安装成功之后进入本地系统/usr/share/bcc查看相关工具