解析各种文件格式 Tika
tika 是什么
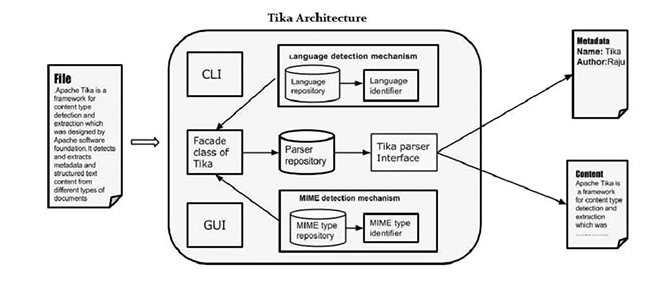
Apache Tika 用于文件类型检测和从各种格式的文件内容提取的库。在内部,Tika使用现有的各种文件解析器和文档类型的检测技术来检测和提取数据。使用Tika,人们可以开发出通用型检测器和内容提取到的不同类型的文件,如电子表格,文本文件,图像,PDF文件甚至多媒体输入格式,在一定程度上提取结构化文本以及元数据。
tika 特点
- 支持上千种不同的文件类型
- 提供了多种实用工具,如tika-app, tika-server等
- 除了Java,还提供了其他编程语言的调用,如Julia,Python
- 扩展性很好,支持自定义文件类型和解析器
tika 组成
tika-core
tika-core是tika的核心,提供了文件类型检测,语言检测,以及解析器框架。tika-core并不包含具体的解析器,而是提供了一个api,实际的解析器实现放在tika-parsers中。
tika-parsers
解析文件
tika-app
tika-app包含了tika核心类库和它的相关依赖,提供了命令行工具和图形用户界面,可以在脚本中使用,并支持管道。
tika-server
一个restful服务,方便和现有应用系统集成:
|
|
tika-bundle
一个OSGi bundle,方便和基于OSGi的应用系统集成
OSGi: 开放服务网关协议,支持模块的动态加载,热拔插,可以在不停机的情况下,让应用程序加载新的模块,并提供新的服务
tika-eval
一个命令行工具,可以批量解析文件,然后把结果保存到数据库,支持多种类型的数据库,如h2,mysql…,默认数据库为h2,使用其他类型的数据库需要在启动时将相关的依赖放到classpath下
tika 设计与实现
tika的核心功能是文件内容分析,这里分析主要有两个含义,一是提取文件的元数据(Metadata),包括文件类型,版本,作者,编辑工具,压缩算法等;二是解析文件得到文本内容(Text),这里的文本是指在相应的阅览软件中打开文件时看到的内容。
为了实现上述目标,tika设计了一个扩展性极强的框架,主要包括文件类型检测和内容解析两个部分。首先判断文件类型(Detector),再根据文件类型选用适当的解析器(Parser),解析结果保存在Metadata和ContentHandler中,我们可以通过自定义ContentHandler来得到想要的信息。