GVariant规范1.0
概念
根据需求,GVariant必须与DBus消息总线系统(在[DBus]中指定)基本兼容。
为此,GVariant中使用的类型系统与DBus中使用的类型系统几乎相同。然而,为了提供一个更好的系统,同时仍然保持高度兼容性,做了一些非常微小的更改;具体来说,可以通过DBus发送的每个消息都可以表示为GVariant。
如果从头开始设计类型系统,则从DBus带入的一些包袱不会出现在类型系统中。例如,对象路径和签名类型是高度特定于dbus的,如果从头创建,则不会出现在通用类型系统中。
GVariant与DBus类型不同点
为了增加概念的清晰度,一些限制已经被取消,允许调用“永不失败”,而不是必须检查这些特殊情况。
- DBus限制了容器类型嵌套的最大深度,而GVariant没有这样的限制;嵌套支持任意深度。
- DBus通过将“签名字符串”限制为不超过255个字符来限制其消息的最大复杂度,而GVariant没有这样的限制;支持任意长度的类型字符串,允许创建具有任意复杂类型的值。
- DBus只允许字典条目类型作为数组类型的元素类型出现,而GVariant没有这样的限制;字典条目类型可以单独存在,也可以作为任何其他类型构造函数的子类型存在。
- DBus要求结构类型至少包含一个子类型,而GVariant没有这样的限制;单元类型在GVariant中是完全有效的类型。
DBus的一些限制是出于安全考虑而施加的(例如,限制处理来自不可信发送方的消息可能导致的递归深度)。如果GVariant的使用方式对这些考虑非常敏感,那么程序员应该在从不可信源输入值到程序时对这些情况进行检查。
此外,DBus没有用于表示可空性概念的类型构造函数。为此,添加了Maybe类型构造函数(在类型字符串中由m表示)。
正在考虑将其中一些更改包含到DBus 2中。
- “nullable type”是一种类型,除了包含其正常值范围外,还包含该范围之外的特殊值,称为NULL、Nothing、None或类似的值。在大多数具有引用或指针类型的语言中,这些类型都是可空的。有些语言能够拥有任何类型的可空版本(例如,Haskell中的“Maybe Int”和“Int ?”i; “在c#中)。
- 在面对面的会议中进行了大量讨论,在DBus邮件列表(http://lists.freedesktop.org/archives/dbus/2007-August/008290.html)上也进行了一些讨论
各种类型
基础类型
Boolean
取值必为 True 或 False 的一种类型
Byte
可以转为 unsigned 类型,取值范围:0 - 255
Integer Types
共有六种类型:16、32和64整数的字节有符号和无符号版本,带符号的版本具有与二补表示一致的值范围。
Double Precision Floating Point
双精度浮点值由IEEE 754精确定义。
String
字符串是零个或多个字节。官方上,GVariant是编码不可知的,但是使用UTF-8是被期望和鼓励的。
Object Path
DBus对象路径,与DBus规范中描述的完全相同。
Signature
与DBus规范中描述的完全相同的DBus签名字符串。由于仅为了与DBus兼容而保留了此类型,因此适用于此类型值范围的所有DBus限制(例如:嵌套深度和最大长度限制)。
容器类型
Variant
变体类型是一个类型(本章描述的任何类型,包括变体类型本身)和该类型的值的依赖对。您可以使用此类型来克服数组的所有元素必须具有相同类型的限制。
Maybe
maybe类型构造函数为任何其他单一类型提供了可空性。区分非空情况,这样当多个maybe类型构造函数应用于一个类型时,可以检测到不同级别的null。
Array
数组类型构造函数允许创建与所提供的元素类型对应的数组(或列表)类型。必须只提供一种元素类型,并且该数组类型的任何实例中的所有数组元素都必须具有该元素类型。
Structure
结构类型构造函数允许创建与所提供的元素类型相对应的结构类型。这些“结构”实际上更接近元组,因为它们的字段没有命名,但是使用“结构”是因为DBus规范是这样称呼它们的。
结构类型构造函数是唯一可变的类型构造函数——可以给出任意自然数的类型(包括0和1)。
Dictionary entry
字典条目类型构造函数允许创建一种特殊类型的结构,当该结构用作数组的元素类型时,意味着数组的内容是键/值对的列表。为了与DBus兼容,这个二进制类型构造函数需要一个基本类型作为它的第一个参数(按照惯例,它被视为键),但任何类型都可以作为第二个参数(按照惯例,值)。
字典条目只是按照惯例这样做;这包括将它们放入数组中以形成“字典”。GVariant没有对字典施加通常期望的限制(例如键的唯一性)。
Strings 类型
与DBus一样,使用简洁的字符串表示来表示类型。
在直接将值作为一阶对象处理的GVariant中,类型字符串(按此名称)是表示单一类型的字符串。
这与DBus中的“签名字符串”形成对比,后者应用于消息,包含零个或多个类型(对应于消息的参数)。
语法
string类型的语言与上下文无关。它也是前缀代码,是语言本身的递归结构使用的属性。
类型字符串可以用无歧义上下文语法来描述。
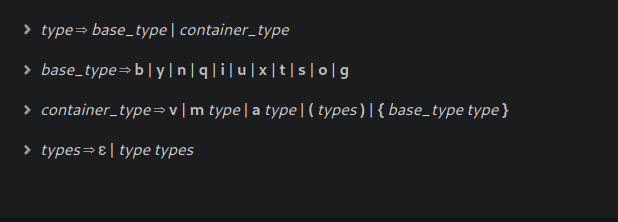
语义
用于从给定语法获取类型字符串的派生将创建描述类型的抽象语法树。通过右边每个包含终端的项推导的效果如下所示:
| 表示 | 含义 |
|---|---|
| b | boolean 类型 |
| y | byte 类型 |
| n | 16-bit 整型 |
| q | 16-bit 无符号整型 |
| i | 32-bit 整型 |
| u | 32-bit 无符号整型 |
| x | 64-bit 整型 |
| t | 64-bit 无符号整型 |
| d | 双精度浮点类型 |
| s | 字符串类型 |
| o | object path 类型 |
| g | signature 类型 |
| v | variant 类型 |
| m |
Maybe类型 |
| a |
数组类型 |
| (types) | structure 类型 |
| {base_type type} | key-value 类型 |
序列化格式
本章描述了GVariant使用的序列化格式。这种序列化格式是新开发的,在这里是第一次描述。
Why not DBus?
由于GVariant在很大程度上与DBus兼容,因此使用DBus的序列化格式(加上适当的修改)作为GVariant的序列化格式是有意义的。
然而,这样做会与为GVariant建立的许多需求相冲突。
最根本的是,需求将被违反。DBus消息以这样一种方式编码:为了从数组中取出第100个项目,您首先必须遍历前99个项目以发现第100个项目的位置。这种迭代的副作用是对需求的违反。
此外,将DBus序列化格式与需求要求的API一起使用可能意味着违反需求,因为DBus消息的子部分在受到不同的起始对齐时可能会改变含义。在简单包含中对此进行了更详细的讨论。
符号
在本节中,将使用一种通用的类型和值表示法提供一些示例。
用于类型的表示法正是类型中描述的类型字符串。
用于值的符号对于Python或Haskell的用户来说都很熟悉。数组(列表)用方括号表示,结构(元组)用圆括号表示。逗号分隔元素。字符串是单引号的。前缀为0x的数字被视为十六进制。
常量True和False表示布尔常数。maybe类型的空值数据构造函数表示为Nothing,一元类型的空值数据构造函数表示为Just。
概念
GVariant值序列化是一个从值到字节序列对和类型字符串的总和单射函数。序列化是确定性的,因为序列化给定值只会产生一种可接受的“标准形式”。序列化是非满射的:非正规形式存在。
如果没有类型string,序列化产生的字节序列是无用的。换句话说,反序列化字节序列需要知道这种类型。
在讨论序列化的细节之前,有一些在格式设计中普遍存在的概念应该被理解。
字节序列
字节序列被定义为一个长度已知的字节序列。在所有情况下,在GVariant中,知道长度对于成功地反序列化一个值是至关重要的。
字节边界
GVariant中使用的开始偏移量和结束偏移量不是指字节位置,而是指字节边界。与长度为n的字符串可以有n + 1个前缀一样,大小为n的字节序列也有n + 1个字节边界。

当谈到字节序列的开始位置时,开始边界的索引恰好对应于第一个字节的索引。然而,当谈到结束位置时,结束边界的索引将是最后一个字节的索引,加1。这个范例非常常用,并且允许指定零长度的字节序列。
简单限制
存在许多具有子值能力的容器类型。在所有情况下,容器的每个子值的序列化字节序列将作为该容器的序列化字节序列的连续子序列出现——与它单独出现时的形式完全相同。子字节序列将按照它们在容器中的位置顺序出现。
容器的职责是能够确定每个子元素的开始和结束(或等价地,长度)。
此属性允许将容器分解为子值,只需引用容器字节序列的子序列作为子值,这是满足需求的有效方法。
此属性不是DBus序列化格式的情况。在许多情况下(例如,数组),DBus消息的子值的编码将根据该值出现的上下文而改变。举个例子:在双精度数组的例子中,如果紧挨着数组前面的值的偏移量是8的偶数倍,那么该数组将包含4个填充字节,如果前一个值的结束偏移量向任何一个方向移动了4个字节,则该数组将不包含这些填充字节。
对齐
为了满足这一要求,我们必须为程序员提供一个他们可以舒适使用的指针。在许多机器上,程序员不能直接解引用未对齐的值,即使在可以解引用的机器上,性能也经常受到影响。
因此,序列化格式中的所有类型都有与之相关的对齐方式。对于字符串或单个字节,这种对齐方式是简单的1,但对于32位整数(例如),这种对齐方式是4。对齐是类型的一个属性——类型的所有实例都具有相同的对齐方式。
所有对齐的值在内存中的起始地址必须是其对齐的整数倍。
容器类型的对齐方式等于该容器的任何潜在子容器的最大对齐方式。这意味着,即使一个32位整数数组是空的,它仍然必须对齐到最近的4字节倍数。这也意味着变体类型(如下所述)的对齐值为8(因为它可能包含任何其他类型的值,并且最大对齐值为8)。
固定大小
为了避免大量的帧开销,可以利用这样一个事实,即对于某些类型,所有实例都具有相同的大小。在本例中,该类型被称为固定大小的类型,其所有值都是固定大小的值。例如单个整数和由整数和浮点数组成的元组。反例是一个字符串和一个整数数组。
如果一个类型具有固定大小,那么这个固定大小必须是该类型对齐方式的整数倍。类型的大小永远不会固定为0。
如果容器类型总是保存固定数量的固定大小的项(例如某些结构体或字典项),那么该容器类型也将是固定大小的。
帧偏移
如果容器包含非固定大小的子元素,则容器有责任确定它们的大小。这是使用帧偏移量完成的。
帧偏移量是某个预定大小的整数。大小总是2的幂。大小由容器字节序列的总体大小决定。它被选择为足够大,以引用容器中的每个字节边界。
例如,大小为0的容器的帧偏移量为0(因为不需要比特来表示没有选择)。大小从1到255的容器的帧偏移量为1(因为256个选择可以用一个字节表示)。从256到65535的容器的帧偏移量为2。大小为65536的容器的帧偏移量为4。
帧偏移量的大小没有理论上的上限。这一事实(以及序列化格式中没有其他限制)允许任意大小的值。
当序列化时,正确的帧偏移大小必须通过“试错”来确定——检查每个大小以确定它是否有效。由于偏移量的大小包含在容器的大小中,因此较大的偏移量可能会使容器的大小上升到下一个类别,这将需要更大的偏移量。但是,这种容器不被认为是“正常形式”。如果序列化的数据是正常形式,则必须使用尽可能小的偏移量。
框架偏移总是出现在容器的末尾,并且是未对齐的。它们总是以小端字节顺序存储。
字节序
尽管序列化数据的帧偏移始终以小端字节序存储,但用户可见的数据(通过要求的接口)允许以大端字节序或小端字节序存储。这被称为“编码字节顺序”。在传输消息时,如果没有明确约定,则应该指定这个字节顺序。
编码字节顺序只影响7种类型值的表示:6种(16、32和64位,有符号和无符号)整型和双精度浮点型。不同编码字节顺序之间的转换是一个简单的操作,通常可以就地执行(但有关例外情况,请参阅Byteswapping注释)。
基础类型序列化
Boolean
布尔值的大小固定为1,对齐方式为1。它的值为True为1,False为0。
Bytes
一个字节的固定大小为1,对齐方式为1。它可以有任何有效的字节值。按照惯例,字节是无符号的。
Integers
有16位,32位,64位有符号整数和无符号整数。每个整数类型的大小都是固定的(到它的自然大小)。每个整型都有与固定大小相等的对齐方式。整数按编码字节顺序存储。有符号整数用2的补数表示。
双精度浮点型
双精度浮点数的对齐方式和固定大小为8。双精度值按编码字节顺序存储。
Strings
包括对象路径和签名字符串,字符串的大小不是固定的,对齐方式为1。任何给定的序列化字符串的大小等于字符串的长度加1,最后一个序列化字节是一个null(0)结束符。没有指定字符串的字符集编码,但是不允许在字符串的内容中出现null字节。
容器序列化
Variants
Variant 是通过存储子对象的序列化数据,加上一个零字节,再加上子对象的类型字符串来序列化的。
零字节是必需的,因为尽管类型字符串是前缀代码,但它们不是后缀代码。在没有此分隔符的情况下,考虑序列化为两个字节的变体的情况- “ay”,这是一个字节,‘a’,还是一个空的字节数组?
Maybes
可能编码不同,取决于它们的元素类型是否固定大小。 maybe类型的对齐方式始终等于其元素类型的对齐方式。
固定大小元素的 Maybe
对于Nothing情况,序列化的数据是空字节序列。
对于Just情况,序列化的数据完全等于子对象的序列化数据。这总是与Nothing情况相区别,因为所有固定大小的值都具有非零大小。
非固定大小元素的 Maybe
对于Nothing情况,序列化的数据同样是空字节序列。
对于Just情况,序列化形式是子元素的序列化数据,后面跟着一个0字节。这个额外的字节确保即使在子值的大小为0的情况下,也可以将Just大小写与Nothing大小写区分开来。
Arrays
数组被称为固定宽度数组或可变宽度数组,取决于它们的元素类型是否是固定大小的类型。这两种情况的编码非常不同。
数组类型的对齐方式始终等于其元素类型的对齐方式。
固定宽度的 Arrays
在这种情况下,每个数组元素的序列化形式被按顺序打包,没有额外的填充或框架,以获得数组。因为所有固定大小的值的大小都是其对齐要求的倍数,而且数组中的所有元素都有相同的对齐要求,所以所有元素都会自动对齐。

数组的长度可以通过取数组的大小并除以固定的元素大小来确定。这将始终工作,因为所有固定大小的值都有一个非零大小。
可变宽度 Arrays
在这种情况下,每个数组元素的序列化形式再次按顺序打包。不过,与固定宽度的情况不同的是,为了对齐的目的,可能需要在元素之间添加填充字节。这些填充字节必须为零。
添加完所有元素后,将按顺序为每个元素添加一个帧偏移量。帧偏移量指定该元素的结束边界。

每个帧偏移量的大小是数组的序列化大小和最终帧偏移量的函数,通过识别数组中最终元素的结束边界也可以识别帧偏移量的开始边界。由于数组中的每个元素都有一个帧偏移量,我们可以很容易地确定数组的长度。
$$ length = (size - last_offset) / offset_size $$
要找到任何元素的开始,只需取前一个元素的结束边界,并四舍五入到数组(因此也是元素)对齐的最近整数倍。第一个元素的开始就是数组的开始。
由于确定数组的长度依赖于我们计算帧偏移量的能力,而帧偏移量的数量是由它们占用的空间决定的,因此零字节的帧偏移量在数组中是不允许的,即使在所有其他序列化数据的大小为零的情况下也是如此。这个特殊的异常避免了用0除以0问题。
Structures
与数组一样,结构是通过存储每个子项来序列化的,顺序与填充字节正确对齐,填充字节必须为零。
在添加了所有项之后,对于结构中不是最后一项的每个非固定大小的项,将以相反的顺序追加一个框架偏移量。帧偏移量指定该元素的结束边界。
帧偏移量以相反的顺序存储,以允许基于迭代器的接口开始迭代结构中的项,而无需首先测量类型字符串所隐含的项的数量(该操作所需的时间与字符串的大小成线性)。
没有为结构中的最后一项存储框架偏移量的原因是,可以通过从结构的大小中减去框架偏移量的大小来确定其结束边界。在给定类型的结构的任何实例中出现的帧偏移量可以完全由类型确定(遵循上面给出的规则)。
固定大小的项目不存储帧偏移量的原因是,通过将固定大小添加到开始边界,始终可以找到它们的结束边界。
要找到结构中任何项的起始边界,只需从前面最近的非固定大小项的结束边界开始(如果没有前面的非固定大小项,则从0开始)。从这里开始,四舍五入对齐,并为每个中间项添加固定大小。最后,舍入到所需项目的对齐位置。
对于随机访问,似乎这个过程所花费的时间与结构中元素的数量成线性关系,但实际上它可以在非常小的常数时间内完成。参见计算结构项地址。
如果结构中包含的所有项都是固定大小的,那么结构本身就是固定大小的。必须考虑满足这个固定大小值的约束条件。
首先,固定大小必须是非零的。这种情况只会发生在单元类型的结构或只包含这种结构的结构(递归地)。这个问题可以通过任意声明单元类型实例的序列化编码为单个零字节(大小为1)来解决。
第二,固定尺寸必须是结构对齐的倍数。这是通过在任何固定宽度结构的末尾添加零填充字节来实现的,直到此属性为真。这些字节永远不会在定位帧偏移量或可变大小子对象的结束时造成混淆,因为根据定义,这些事情都不会发生在固定大小的结构中。
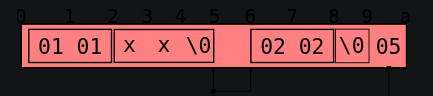
图2.4描述了类型(nsns)和值[257,‘xx’, 514, “]的结构。对于不是最终项的非固定大小的项(即字符串’xx’),存在一个帧偏移。说明了“舍入”以找到第二个整数的开始的过程。
Dictionary Entries
字典条目被视为只有两个项的结构——首先是键,然后是值。在键大小固定的情况下,将没有帧偏移,而在键大小非固定的情况下,将只有一个帧偏移。由于该值被视为结构中的最后一项,因此它永远不会有帧偏移。
例子
本节包含一些说明序列化格式的示例。所有示例都是小端字节顺序。
示例数据每行给出16个字节,每个字节的值由两个字符表示。为了清晰起见,根据不同的目的,字节值使用了许多不同的表示法。
|
|
每个例子都指定了一种类型、一个字节序列,以及当用给定类型反序列化时,这个字节序列所代表的值。
- String Example
使用类型's',表示'hellow world':
|
|
- Maybe String
使用类型 'ms', 表示 Just 'hello world'
|
|
- Array of Booleans Example
使用类型 'ab',表示[True, False, False, True, Ture]
|
|
- Structure Example
使用类型'(si)',表示('foo', -1).
|
|
- Structure Array Example
With type 'a(si)',has a value of [('hi', -2), ('bye', -1)].
|
|
- String Array Example
With type 'as',has a value of ['i', 'can', 'has', 'strings?'].
|
|
- Nested Structure Example
With type '((ys)as)',has a value of (('i', 'can'), ['has', 'strings?']) :
|
|
- Simple Structure Example
With type '(yy)',has a value of (0x70, 0x80).
|
|
- Padded Structure Example 1
With type '(iy)',has a value of (96, 0x70).
|
|
- Padded Structure Example 2
With type '(yi)',has a value of (0x70, 96).
|
|
- Array of Structures Example
With type 'a(iy)',has a value of [(96, 0x70), (648, 0xf7)].
|
|
- Array of Bytes Example
With type 'ay',has a value of [0x04, 0x05, 0x06, 0x07].
|
|
- Array of Integers Example
With type 'ai',has a value of [4, 258].
|
|
- Dictionary Entry Example
With type '{si}',has a value of {'a key', 514}.
|
|
非正常序列化数据
名义上,反序列化是序列化的逆操作。这意味着反序列化应该是一个双射部分函数。
如果反序列化是一个局部函数,则必须对序列化的数据不是正常形式的情况进行处理。通常这将导致引发一个错误。
反对错误的观点
要求XXX禁止我们在加载时扫描整个序列化的字节序列;我们现在不能检查是否正常,也不能发布错误。这使得任何可能发生的错误在访问值时作为异常引发。
由于C语言对异常的支持很差(几乎不存在),并且考虑到对简单数据值的任何访问都可能失败,这种解决方案也很快变得站不住脚。
在给定约束条件下,处理错误的唯一合理解决方案是将它们定义为不存在。接受非正规形式的序列化数据使反序列化成为一个满射(但非单射)的总函数。所有字节序列反序列化为某个有效值。
出于安全考虑,对非正常值执行的操作是精确指定的。可以很容易地想象这样一种情况:内容过滤器对消息的内容起作用,调节对安全敏感组件的访问。如果可以创建一个由过滤器中的反序列化程序和安全敏感组件中的反序列化程序以不同方式解释的消息的非标准形式,则可以“偷偷通过”过滤器。
默认值
当反序列化过程中遇到错误,无法引发异常时,我们被迫进入必须返回预期类型的有效值的情况。因此,为每种类型定义了一个“默认值”。这个值通常是在反序列化过程中遇到错误的结果。
有人可能会说,健壮性的降低是因为忽略错误并向用户返回任意值。不过,应该指出的是,对于大多数类型的序列化数据,一个随机字节错误更有可能导致数据保持正常形式,但值不同。我们无法捕获这些情况,并且这些情况可能导致将给定类型的任何可能值返回给用户。我们被迫接受这样一个事实:在存在损坏的情况下,我们所能做的最好的事情就是确保用户接收到正确类型的一些值。
每种类型的默认值为:
| 类型 | 默认值 |
|---|---|
| Boolean | False |
| Bytes | nul |
| Integers | 0 |
| Floats | 0 |
| String | 空字符串 |
| Object Paths | ‘/’ |
| Signatures | 空字符串 |
| Arrays | 空 |
| Maybes | 类型的Nothing |
| Structures | 每个元素的默认值 |
| Dictionary Entries | 每个元素的默认值 |
| Variants | 包含单元类型的子变量 |
处理非正常序列化数据
在一个正常运行的系统上,通常不会遇到非正常值,因此一旦检测到问题,即使性能任意差也是可以接受的。但是,出于安全原因,在访问不受信任的数据时,必须始终检查其是否正常。由于这些检查的频率,它们必须是快速的。
本节中包含的几乎所有用于非正常数据反序列化的规则都要记住这一要求。具体来说,所有规则都可以在一个很小的常数时间内确定(有几个非常小的例外)。这是不允许的,例如,要求在其帧偏移量中任何地方都不一致的数组被视为空数组,因为这将需要扫描所有偏移量(数组的大小是线性的),只是为了确定数组的大小。
在序列化的字节序列中,只会发生少量不同种类的异常。每一个问题,以及该怎么做,都将在本节中讨论。
下面的列表是一个明确的列表。如果一个序列化的字节序列没有这些问题,那么它就是正常的形式。如果一个序列化的字节序列有任何这些问题,那么它就不是正常的形式。
-
固定大小值中错误的大小:如果用户尝试使用固定宽度类型的类型和错误长度的字节序列进行反序列化,则将使用该类型的默认值。
-
非零填充字节:当任何填充字节非零时,会发生此异常。这适用于数组、maybe、结构和字典条目。这种异常永远不会被检查——子值从它们的容器中反序列化,就好像填充是零一样。
-
布尔值超出范围:如果一个布尔值中包含的数字不是0或1,那么它就会被视为真值。这是为了与用户直接在C中访问一个布尔数组保持一致。例如,数组中的一个字节包含数字5,在C中这将计算为True。
-
可能未终止字符串:如果字符串的序列化形式的最后一个字节不是零字节,则字符串的值将被视为空字符串。
-
带有嵌入式空字符的字符串:如果一个字符串的最后一个字节是null字符,但在这个最终结束符之前还包含另一个null字符,则该字符串的值将被取为嵌入的nul之前的字符串的一部分。这意味着获取一个指向字符串的C指针仍然是一个常数时间操作。
-
无效对象路径:如果对象路径的序列化形式不是一个有效的对象路径,后面跟着一个零字节,则使用默认值。
-
无效的签名:如果签名字符串的序列化形式不是一个有效的DBus签名,后面跟着一个零字节,则使用默认值。
-
可能是固定尺寸的尺寸错了:如果具有固定元素大小的实例不完全等于该元素的大小,则将该值取为Nothing。
-
固定宽度数组的大小错误:如果固定宽度数组的序列化大小不是固定元素大小的整数倍,则取该值为空数组。
-
子对象的开始或结束边界落在容器之外:如果帧偏移量(或基于帧偏移量的计算)表明子值的字节序列的任何部分将落在父值的字节序列之外,则为子值提供其类型的默认值。
-
结束边界先于开始边界:如果帧偏移量(或基于帧偏移量的计算)表明子值的字节序列的结束边界在其开始边界之前,则为子值提供其类型的默认值。在开始边界之前的子节点的结束边界可能导致两个或多个子节点的字节序列重叠。其他子节点将忽略此错误。这些子节点的值对应于在这些字节序列上执行的正常反序列化过程,该过程具有子节点类型。如果容器中的子容器顺序不一致,则表示存在这种异常。没有对顺序不一致的子节点执行其他特定的检查。
-
子值重叠帧偏移:如果子值的字节序列与其所在容器的帧偏移量重叠,则此错误将被忽略。子进程被赋予一个值,这个值对应于在这个字节序列上执行的正常反序列化过程(包括来自帧偏移的字节),该字节序列具有子进程的类型。
-
非固定宽度数组的无意义长度:如果非固定宽度数组的最终分帧偏移量指向数组字节序列之外的边界,或者表明数组中存在非整数值的分帧偏移量,则将该值视为空数组。
-
结构帧偏移空间不足:如果序列化结构包含的空间不足以存储所需的帧偏移量,则只要正在访问的项具有所需的帧偏移量,错误就会被无声地忽略。试图访问需要偏移量超过可用偏移量的项将导致默认值。